




There is a growing consensus forming across the legal tech ecosystem among founders, engineers, and increasingly lawyers themselves, that something subtle but important has shifted in how legal AI products are built.
The term “vibe coding” has started to circulate at a rapid pace. In practice, it refers to a development approach where AI-assisted tools dramatically reduce the time required to build functional software. In legal AI, that shift is now visible in a new class of tools: systems that replicate familiar workflows, from document review, assistants, and project-based workspaces, built in weeks rather than months.
“Mike,” an open-source legal AI project, has become one of the more visible examples of this change. Its positioning is explicit. It presents itself as an open alternative to enterprise tools such as Harvey and Legora, with comparable core features and the option to self-host.
Across the legal tech community, however, the reaction has been notably measured. Rather than framing tools like Mike as replacements, most commentary has treated them as signals: indicators of what has become easier to build, and what remains structurally complex.
Rebuilding the application layer
Mike reconstructs what many now recognise as the standard application layer. It includes assistants, tabular review, project-based document workspaces, and workflow libraries, and according to many vibe-coders, it’s even reaching near parity with the core functionality of existing enterprise tools.
What stands out is not just the feature set, but the speed at which it was assembled. That speed reflects a broader shift in development: mature model APIs, accessible infrastructure, and tooling that abstracts much of the underlying engineering effort.
This raises a more technical question that sits at the centre of the current discussion. If these systems can now be rebuilt relatively quickly, where does the difficulty arise? Is it in constructing the visible workflows and interfaces, or in the underlying systems that allow them to function reliably?
This week, The Legal Wire spoke with founder Will Chen, about the architecture behind Mike, the shifting economics of legal AI development, and why the gap between prototype and production matters more than ever.
TLW: Mike appears to recreate, to an extent, the application layer of several enterprise legal AI tools, i.e., projects, assistants, tabular review, workflows, document context, and citation. From a technical perspective, which part was genuinely difficult to build, and which part became relatively straightforward once the model APIs and document architecture were in place?
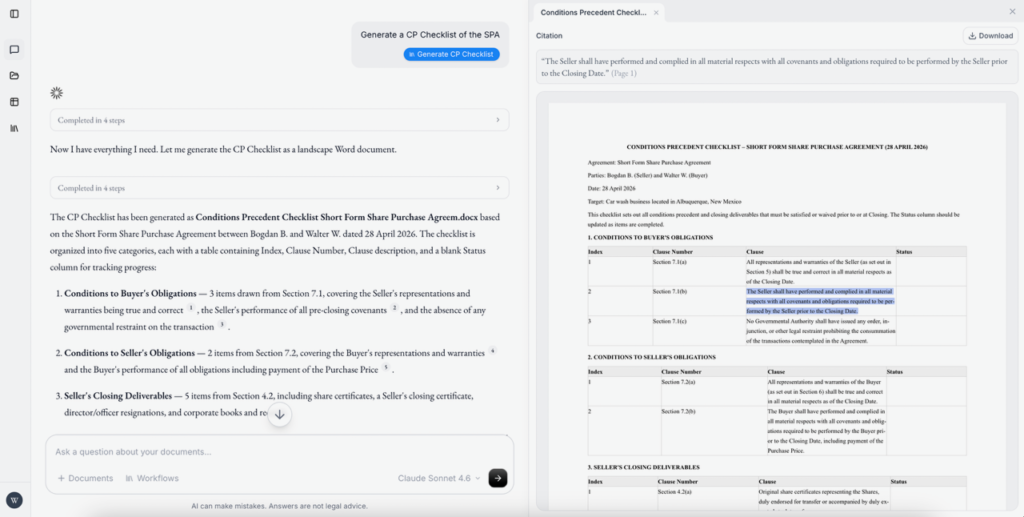
Will: “Due to differences in complexity of the code required, the parts that were difficult included designing tools to allow the agent to create and edit Word documents reliably and to produce accurate citations back to source material. Another difficult part was figuring out a cohesive design language that was simple, clear and accessible to lawyers. The parts that were relatively straightforward were building out the frontend scaffolding once the design framework and agent tools had been figured out.”
Retrieval, context, and reliability
Once the application layer is in place, the complexity moves toward retrieval and context management. Legal AI systems are not simply generating outputs; they are expected to retrieve the correct information, maintain context across documents, and provide traceable citations.
This introduces a different class of engineering challenges. Decisions around chunking, embedding strategies, and retrieval pipelines directly affect output quality. Even small changes in how documents are processed can significantly alter the reliability of the system.
These issues are often less visible in demos, but they become critical in practice, particularly when systems are applied across large and varied document sets.
TLW: In systems like Mike, retrieval quality and source attribution are central to legal use cases. How did you approach document chunking, embeddings, and citation tracing, and where do you see the current technical limitations of these methods in practice?
Will: “Because Mike is open source, its retrieval approach is inspectable rather than hidden behind a black box. I deliberately did not build Mike around a traditional RAG pipeline of chunking documents, embedding them, and retrieving semantically similar fragments. For legal work, that approach can be brittle: once a contract or pleading is broken into small chunks, important context, definitions, cross-references, and document structure can be lost.
Mike instead takes a more agentic approach, similar to how coding agents like Codex and Claude Code operate. The system gives the model tools to read documents, search within them, and work from extracted source text rather than relying only on embedding similarity. That can be more token-intensive, but it keeps the model closer to the underlying document and makes citation tracing more transparent.
I still think embeddings and RAG have a role, especially for discovery, ranking, and navigating large collections. But in legal workflows, retrieval should not just find something that sounds related. It needs to preserve context and support claims with traceable source material. That is the bar Mike is designed around.”
From prototype to production
Mike is positioned as both functional and exploratory. It’s capable of being used in smaller environments, but not yet tested at the level required for large-scale institutional deployment. That distinction echoes a broader view across the market. Prototypes are becoming easier to build, but production systems remain materially more complex.
Much of the difference lies in layers that are not immediately visible, such as security, permissions, auditability, and system reliability. All of these elements become central when tools move into real legal environments. But these are not challenges that can be fully addressed through rapid prototyping alone.
As a result, the conversation is developing from what can be built to what can be safely deployed.
TLW: Enterprise legal AI platforms often differentiate on governance layers such as permissions, audit logs, and compliance workflows. Architecturally, what would need to be added or fundamentally reworked in Mike to support fine-grained access controls, auditability, and multi-tenant environments at scale?
Will: “Mike’s current architecture is intentionally lean: it centers on authenticated users, project/document ownership, and shared access around practical workflows. To support enterprise-scale legal deployments, we would need to deepen that foundation into a full tenant-aware authorization model. That means introducing organization and workspace boundaries as first-class entities, role-based or attribute-based permissions, and policy enforcement consistently across the API, database, storage, and AI tool layers.
For auditability, the system would need append-only event logs that capture who accessed, modified, shared, exported, or generated content, with immutable timestamps and enough context for legal and compliance review. On the compliance side, we would add retention policies, data residency controls, admin visibility, key management, and stronger controls over model routing and logging. The important architectural shift is moving from user-centric security to organization-centric governance, where every object, request, AI action, and document operation is scoped to a tenant and governed by explicit policy.”
Where the complexity resides
As the application layer becomes easier to replicate, the focus within legal tech is moving toward a more precise understanding of where complexity resides. There is increasing debate over whether the real technical moat lies in the model itself, the workflow design, or the infrastructure that governs how systems operate in practice.
Some argue that the industry has overestimated the difficulty of building legal AI applications, pointing to the accessibility of modern tools. Others suggest that the true complexity has always been in deployment, integration, and long-term system management.
This distinction, between building and operating, is becoming more central to how both developers and buyers evaluate legal AI systems.
TLW: From your experience building Mike, where does system complexity increase most sharply? Is it at the level of user interface orchestration, backend architecture, or model interaction? And how does that compare to how the market currently perceives complexity in legal AI?
Will: “From building Mike, the sharpest complexity is not in any single layer, but in the handoff between layers. The user interface has to make legal work feel structured and predictable, the backend has to preserve permissions, document state, versions, and citations, and the model layer has to operate inside those constraints without inventing facts or losing context. The design of Mike addresses these complexities.
The market tends to describe legal AI complexity in terms of enterprise requirements: integrations, security, compliance, deployment, and change management. But at the product architecture level, a lot of the difficulty shows in orchestration: connecting documents, workflows, edits, citations, review tables, chat history, permissions, and outputs into one reliable system. The model matters, but the product value comes from making AI behave as part of a governed legal workflow rather than as a standalone interface.
Mike seeks to prove that a small team of lawyers and engineers, who understand these complexities and addresses them well, can catch up very rapidly with the incumbents in this new age of AI-enabled software development.”
Evaluation and trust
In legal contexts, system performance cannot be measured solely by output fluency. Reliability, consistency, and traceability are equally important. This introduces the need for structured evaluation frameworks that go beyond surface-level testing.
Assessing hallucination rates, verifying citation accuracy, and ensuring consistency across different legal domains are all part of building systems that can be trusted. These challenges are shared across both open-source and enterprise platforms, though they are often addressed in different ways.
TLW: How do you think about evaluation in a system like Mike? What frameworks or methodologies would be required to systematically assess output reliability, hallucination rates, and legal accuracy across different document types?
Will: “In Mike, evaluation has to be workflow-based, not just answer-based. Legal AI should be tested on the tasks lawyers actually perform: extracting obligations, comparing documents, drafting from source materials, editing clauses, and producing traceable citations.
I’d evaluate three things systematically: whether cited text actually exists and supports the claim, whether outputs stay consistent across runs and document types, and whether legal conclusions match expert-reviewed benchmarks. This needs to run continuously whenever models, prompts, or workflows change.
Evaluations should be designed by experienced lawyers and assessed on the basis of realistic legal workflows.”
Self-hosting and operational responsibility
The ability to self-host introduces a different set of trade-offs. While it offers greater control over data and infrastructure, it also shifts responsibility for security, maintenance, and performance onto the organisation deploying the system.
For some firms, this may represent an opportunity to build internal capabilities, and for others, it may reinforce the value of external platforms that abstract these responsibilities.
The decision is not as much regarding capability as it is appetite for operational ownership.
TLW: Self-hosting addresses concerns around data control and vendor lock-in, but it also introduces operational responsibility. What infrastructure and security considerations would a firm need to address before deploying a system like Mike in a controlled legal environment?
Will: “Self-hosting should not mean every firm has to reinvent the operating model from scratch. One of the advantages of Mike being open source is that the community can help turn best practices around identity, access control, encrypted storage, secrets management, audit logging, monitoring, and deployment into repeatable patterns that firms can adopt out of the box.
For a controlled legal environment, firms still need to think carefully about data flows, model access, retention, backups, and incident response. But the goal with Mike is to make that operational responsibility more transparent and more manageable. Open source gives firms control over their infrastructure while allowing the community to harden the deployment patterns over time, so self-hosting becomes a practical option rather than a bespoke engineering project.”
A changing relationship between firms and vendors
As more lawyers experiment with building or modifying their own tools, the relationship between law firms and vendors may begin to shift. Buyers are increasingly able to distinguish between what can be built internally and what requires external support.
This could lead to more informed procurement decisions and a clearer understanding of where vendors provide value, particularly beyond the application layer.
TLW: If more lawyers are able to prototype legal AI tools themselves, how do you think that changes the relationship between law firms and vendors? Does it push vendors toward deeper infrastructure and governance layers, or toward rethinking how they price and position application-layer features?
Will: “Greater technical literacy among lawyers will put pressure on thin wrappers. If a product is a polished but generic interface around a model, firms will increasingly understand that and question the premium attached to it.
The vendors that survive will be the thick wrappers: systems that embed AI into real legal workflows, which offer real product differentiation and specialized features that ChatGPT or Claude do not provide. A word add-in for example, will no longer be enough as both Claude and Microsoft have that now. As lawyers become more capable of prototyping, vendors will need to prove that they are not just packaging access to a model, but adding durable infrastructure and workflow value that firms would not want to rebuild themselves.”
What it takes to run this in practice
What emerges from the rise of tools like Mike is not a simple narrative of disruption, but a more nuanced shift in understanding.
The application layer of legal AI is becoming easier to prototype. The infrastructure required to deploy, govern, and maintain these systems at scale remains complex. That distinction is informing how the legal tech community is interpreting “vibe coding”: not as a replacement for enterprise platforms, but as a lens through which the structure of legal AI is becoming clearer.
Rather than collapsing the market into a single direction, this shift is expanding it. Enterprise platforms, internal builds, and open-source tools are increasingly coexisting, each serving different roles depending on scale, risk tolerance, and technical capability.
The conversation is no longer centred on whether legal AI can be built. It is moving toward a more precise question: what does it take to run it responsibly.




