




Roughly four hundred regulatory updates are released every day in the United States. Each year, more than one hundred and thirty thousand bills are introduced, and across all levels of government, the total volume of legislative and regulatory changes runs into the millions.
For any organisation whose operations sit downstream of policy, which is to say nearly all of them, this volume is not just unwieldy. It is structurally hostile to the way most legal and government affairs teams have historically worked.
The traditional response has been to set up keyword alerts, subscribe to a tracking service, and hope that the words a team chooses today will be the same words used by a legislative drafter tomorrow. They rarely are. A privacy bill might never use the phrase “data broker.” A tax measure might affect a beverage manufacturer without mentioning sugar. The keyword paradigm, in other words, asks the user to predict the language of laws that have not yet been written, which is a peculiar thing to ask of anyone.
Abstract, a New York-based policy intelligence platform that began as an AI research project in the dorm rooms of Loyola Marymount University, has been building toward a different premise. Rather than asking the user to describe what they are looking for, the system tries to learn what the organisation really is and then works backwards from there. It is a small reorientation on paper. In practice, it changes a fair amount about what the resulting product looks like.
Notably, the payoff continues later in the workflow than many other monitoring tools go. While telling a client what changed is useful, Abstract brings even more value by carrying the same context forward into impact analysis and strategy.
From a college research project to a policy intelligence platform
Abstract is six years old, but the product that exists today is considerably newer than that. The company started as an AI research project, with co-founders studying electrical engineering and computer science at the time. The original ambition, by Pat Utz‘s own description, was the kind of thing one might expect from undergraduates with access to early language models and a healthy disregard for incrementalism: use AI to summarise and demystify legislation, and in doing so, make government a little more transparent for the people it governs.
That mission has held remarkably steady. The commercial path to it, however, has taken some turns. Abstract spent three years selling software to lobbyists, growing to more than two hundred lobbying firms in California before pivoting again toward law firms and corporate legal teams. The original lobbyist product has since been retired. In January 2025, the company closed a five million dollar seed round to fund development of its current product, and the corporate name, Washington Abstract, remains as a small artefact of those early days building a tool to make Washington legible during the first Trump administration.
Six years in, the company sits in a curious position. It is a legal tech product that did not start in legal tech, built by founders whose original interest was less in serving lawyers than in fixing a problem with the public-facing texture of democratic government. The commercial product has matured beyond that older instinct rather than around it.
TLW: Abstract began as a project aimed at making government more transparent for the public, and has evolved into a commercial platform serving law firms and corporate teams. How do those two ambitions sit together today, and is there anything from the original consumer-facing mission that still shapes how you build the product?
Pat:“The original mission is still 100% core to how we build. Everything we’ve assembled for the commercial side, the insights and data around regulations, legislation, and policy, we intend to make available to the public in a version built for them. Our mission is to make government more accessible and more transparent, and we believe the platform we’re building for the private sector lifts all in parallel.”
The “intelligence layer” and the problem with keywords
The most substantive distinguishing feature of Abstract, and the one Pat returns to most readily, is what the company calls an “intelligence layer.” In essence, it is a structured profile of the client organisation, assembled from two sources: public material (websites, press releases, statements, and deep research that the system conducts on its own), and any private context that the client chooses to upload directly into the platform.
That profile is then used to score and filter legislative and regulatory activity across whichever jurisdictions the client cares about. The practical consequence is that Abstract can surface a bill whose text never uses the client’s industry terminology. A newspaper publisher might need to track subscription opt-out legislation that says nothing about news organisations; armed with context about the publisher’s revenue model, Abstract can make that connection on the publisher’s behalf.
As Pat explains, context should be thought of as all an organisation’s web pages and all the deep research found about them. Abstract then takes all that information and turns it into specific keywords that it matches and scores all the bills by.
There is, of course, a familiar concern with this kind of system. If the platform is doing the inference on the client’s behalf, how does the client know what the platform is truly looking for? Abstract has been rolling out a feature that surfaces the full list of synonyms and contextual keywords the system is using on behalf of a given client, which is a useful transparency mechanism and a sensible response to the black-box anxieties that come with AI-driven matching. One can imagine a more cynical product team simply asking users to trust the algorithm. Abstract has elected, fairly, to show its working.
TLW: The intelligence layer is essentially a model of what the client is, built from public and private context. Where have you found it works best, and where have you found it still struggles? Are there industries or business models where the inference is harder to get right, and how do you think about closing those gaps over time?
Pat: “It works best when a company is publicly legible: lots of material about what it actually does, its products, its labor footprint. It also works well when customers securely upload their relevant internal files into Abstract, which is sandboxed and SOC 2 compliant. Where it still struggles is when a company’s real operations look quite different from what it shows outwardly, and they don’t give us that internal context. At the end of the day, it’s about context, and context that’s well structured. That’s why we’ve done a lot of work educating firms and companies on how to structure their data so the inference can work better.”
Why the data layer, not the workflow, is the moat
If one were to chart the conversational gravity of an hour with Pat, it would settle quite firmly on the question of data. This is partly a function of the moment we are in. Workflow software, broadly conceived, is having a difficult year. Agents are now sufficiently capable that a meaningful share of what used to be sold as a workflow can be assembled, on the fly, by a general-purpose tool. Pat is fairly direct about the implication, suggesting that organisations without either a proprietary data moat or a workflow that is genuinely unbeknownst to the public should give some thought to whether their current business model survives the next twelve months.
Abstract’s response to that pressure is to invest in the layer underneath the workflow. The company builds its own data pipelines, pulling from all fifty state legislatures, federal agencies, and a broad range of local jurisdictions, including cities, counties, and special districts.
For clients that need coverage of thousands of municipalities, Abstract has developed an agentic approach that proactively goes hunting for relevant activity even where no pre-built pipeline exists. Historical data extends back ten to twenty years, depending on the legislature, which makes longitudinal analysis possible in a way that most monitoring tools do not.
The bet, in other words, is that the value of structured, comprehensive government data is going up rather than down. As more of the analytical work becomes commoditised by general-purpose models, the question of who has the right data, cleaned and structured, becomes harder to answer well. It is also a visible theme in the wider market, where structured data feeds have become an attractive acquisition target for larger legal information providers.
TLW: You’ve made the case that data is the durable moat, not the workflow. What does that mean for how Abstract is built and resourced internally? And how do you think about the risk that, over a longer horizon, even structured government data becomes commodity infrastructure?
Pat: “Right now in the AI race, the moat is data: data that isn’t easily scrapable from the public web, plus the proprietary steps and ways of doing the work that aren’t documented anywhere public. Over time, those steps and that data get folded into the foundational models and stop being a moat. At that point, the question becomes which canvas you want to work in, which UX you choose to actually do the job. Everyone is taking a slightly different approach to that, which I find interesting. But for structured government data, the full solution is much further out than people assume.”
Discovery, impact, and strategy
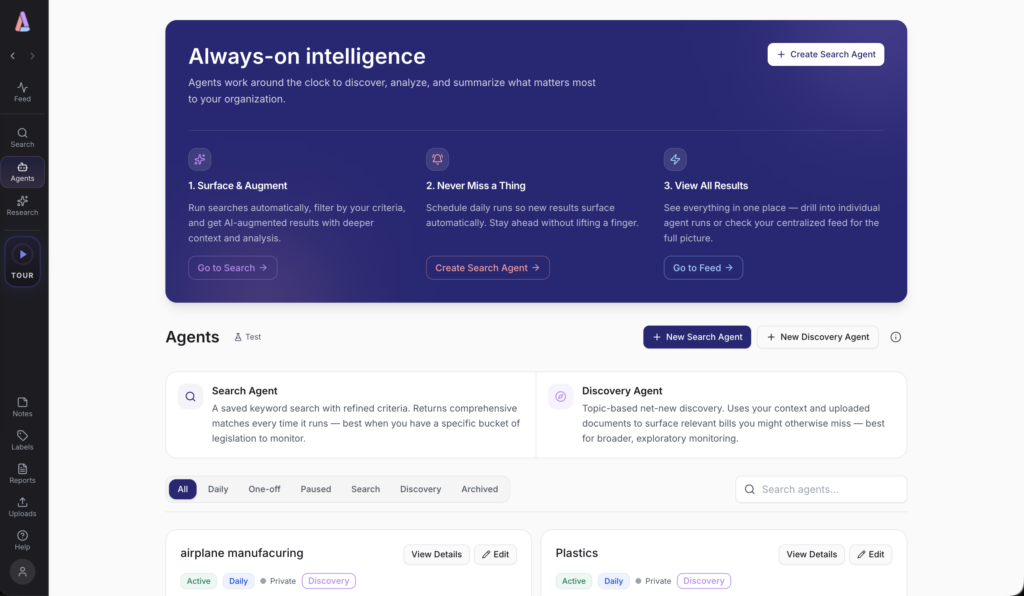
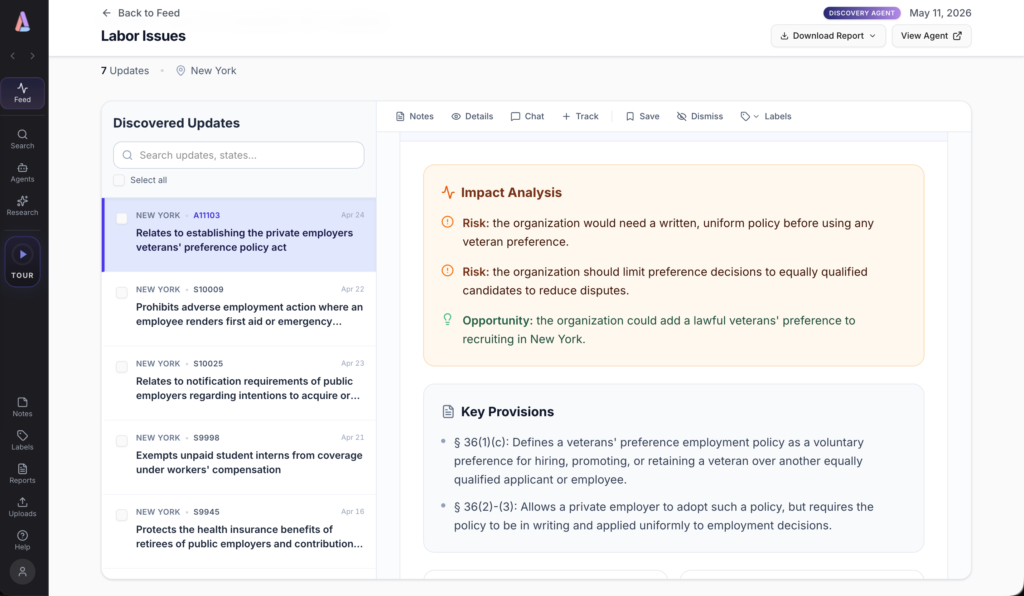
Most monitoring tools stop once they have shown the user what changed. Abstract is built around three connected workflows – Discovery, Impact, Strategy – and the latter two are where the product begins to look meaningfully different from what is on the market.
Discovery is the daily feed of what has changed across the jurisdictions a client cares about, surfaced through the intelligence layer. Impact reports go considerably deeper. For a given bill or regulation, the platform produces a structured analysis of how the development would affect a client fiscally, operationally, and strategically, accompanied by stakeholder maps, talking points designed to neutralise opposition, and recommended next steps. The reports are, in effect, the kind of memorandum that a sufficiently well-briefed associate would produce in a long afternoon, now generated in minutes.
The strategy layer, in turn, was developed in collaboration with experienced lobbyists and incorporates frameworks drawn from professionals in the field. The system can map stakeholders, suggest optimal timing for testimony or amendment proposals, and lay out a go-forward playbook for a piece of legislation. It also integrates contact information for legislative staffers through a data partnership, which is a practical detail that meaningfully distinguishes it from simply asking a general-purpose model to draft a strategy.
How well does any of this hold up in practice? In a demonstration, Pat ran an impact report on a Massachusetts journalist shield bill that the reviewing lobbyist was actively working on. The output correctly identified the bill’s current committee, the procedural bottlenecks holding it up, and the key deadline. None of those are details that a general-purpose model would reliably get right without considerable hand-holding.
TLW: The strategy layer was shaped with input from lobbyists. How did that collaboration change what the product became, and what does it teach you about where human expertise still needs to sit inside a product like Abstract, both during development and once a client is using it day to day?
Pat: “Working with lobbyists taught us how much of the job isn’t publicly available on the web. There are insights you only get by sitting with practitioners and watching how they actually operate. Over time, as more work is done through foundational models, that expertise gets folded in, and the models start carrying the craft of each vertical with them. But for now, that human expertise isn’t on the web, and that’s the gap our system has to bridge. The other piece is that people don’t want to talk to an AI when it comes to the final say. In lobbying, in sales, even in law, the final call still has to be human. That part of the job AI won’t replace.”
Agents, MCP, and the bifurcation of the market
Pat’s view of the broader legal tech landscape is that three things will happen at once. Some firms and corporates will lean heavily into general-purpose tools, particularly as those tools acquire the ability to operate across third-party software, from Outlook to Excel to the long tail of internal systems. Others will continue trying to build internally, encouraged by open-source projects. And a third group will continue to pay vertical AI companies, such as Harvey and Legora, to figure it all out on their behalf, because they prefer outcomes over maintenance.
Abstract’s approach is to participate in the first and third of those without being captured by either. The company is building an MCP connector so that Abstract’s data can be used by external agents directly, which means that a Claude agent would be able to query Abstract for policy intelligence the same way it would query a calendar or a spreadsheet. The interface, the canvas as Pat called it, still matters, because the analysis layer benefits from a place to be reviewed and refined. But the data sits beneath it, available to whichever agent the user prefers to deploy.
Underneath all this is a thesis about who moves first. Pat draws a sharp line between large corporate enterprises and established law firms on one side, and smaller companies and firms on the other. The former, he suggests, are still in the process of getting access to Gemini, with some running only on Copilot, and will take six to twelve months to feel the full force of what agentic systems can do. The latter are already being reshaped in real time. The implication, for legal tech, is that there is still a decent window to sell workflow tools into large institutions, and a considerably shorter one to sell them to anyone else.
TLW: You’ve described a bifurcation between large enterprises that are still catching up and smaller organisations that are already being reshaped by agents. What does that mean for how Abstract sells, supports, and develops for those two groups, and do you anticipate the gap narrowing or widening over the next twelve to eighteen months?
Pat: “The gap is going to close significantly, and very quickly. Right now, a lot of people are still asking for tools with an AI-assisted layer. What’s happening with smaller organizations is that we’re leaning into agents that do the work end to end. The idea is that the agents would do the full job for you, and you won’t need to use a tool anymore.”
Where Abstract fits
The most useful way to situate Abstract in the legal tech market is probably this: it is a vertical AI company whose principal investment is in the data layer beneath the analytical workflow, in a category where the analytical workflow is increasingly under pressure from general-purpose tools. The intelligence layer is the front-of-house feature, and it is a genuinely substantive one, but the more interesting structural decision is the one underneath: build the pipelines, own the data, and let agents talk to it through standardised interfaces.
For a law firm or corporate team whose policy exposure spans multiple jurisdictions, particularly where in-house subject matter expertise is thin, that combination is a reasonable thing to be looking for. For the wider legal tech market, Abstract is also a clean illustration of where the durable value is likely to sit over the next few years.




